|
http://Ka.rsten-Winkler.de |
| Home » hypKNOWsys » Project WUM » WUM Tutorial |
This small tutorial should enable you to start the Web Utilization Miner WUM, to create a new demo mining base, to import the first demo log file that comes with this distribution, to create the visitors' sessions contained in this log file, to build the aggregated log and to execute your first MINT query with the MINT query processor. It covers the basic techniques that you should know about before mining your own log files with WUM. Advanced techniques in using WUM are covered by the second part of the tutorial. It is strongly recommended to work your way through both parts of the tutorial before starting your own mining session.
It is assumed that you successfully installed the Web Utilization Miner on your system and modified all necessary configuration files. If you did not install WUM yet, please refer to the Installation Guide that is part of this User Documentation and continue with the installation of this mining software. The demo version of WUM is supposed to be pure Java. Therefore is should run without difficulties on all existing Java Virtual Machines supporting Java 1.2.2 or higher. Please note that this Web Utilization Miner is a beta version intended for use in research and education. The WUM team would really appreciate to get all kinds of bug reports and feature suggestions for the future development of this software. Simply drop us an e-mail. Good luck in exploring WUM: The Web Utilization Miner.
Alternatively, you may be interested in reading what others write about WUM:
Felix Schendel. Web-Usage-Mining: Analyse vorhandener Technologien und kombinierter Einsatz für kennzahl- und effizienzorientierte Analyse von Server-Logfiles. Projektdokumentation, Fachbereich Wirtschaft, Hochschule Wismar. Wismar, Germany, January 2004. In German. [PDF File, Mail, Web]
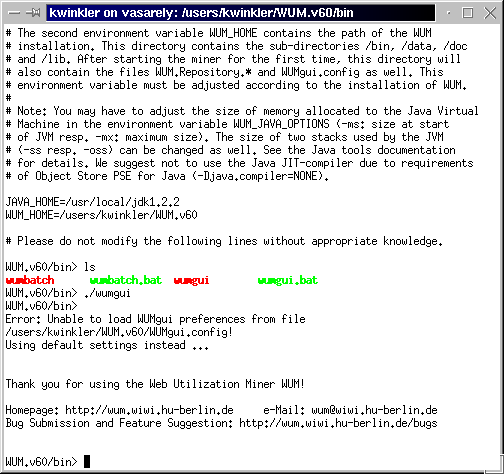
UNIX and Linux: Open a new X-Terminal and make sure that your current
working directory is the bin/ subdirectory of the WUM_HOME
directory. In the given example, the environment variable JAVA_HOME
is set to /usr/local/jdk1.2.2 and WUM_HOME is set to
/users/kwinkler/WUM.v60. The miner can be started as a background
process by executing the shell script wumgui.
Windows 95/98/NT: Open the Windows Explorer by right-clicking the Start
icon of your task bar and selecting Explorer, open the home directory of
WUM by browsing the tree view of your file system and finally double-click the
icon corresponding to the file startwum.pif. Using Linux and the
K-Desktop Environment, the main frame of the Web Utilization Miner may look like
this. The main window of WUM can be resized or moved on your desktop without
difficulties.
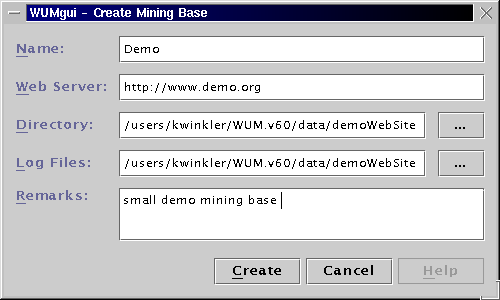
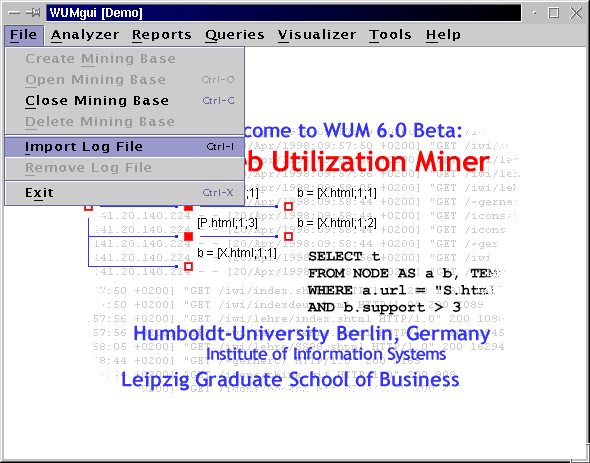
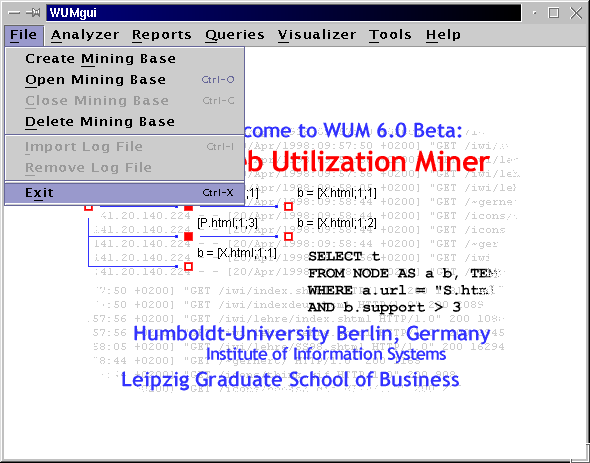
Each mining project requires a mining base within WUM. A mining base contains descriptive information as well as an Object Store PSE Pro database and various other files created by the miner during the mining process. In order to create a new mining base for this tutorial, please open the File menu and select Create Mining Base.
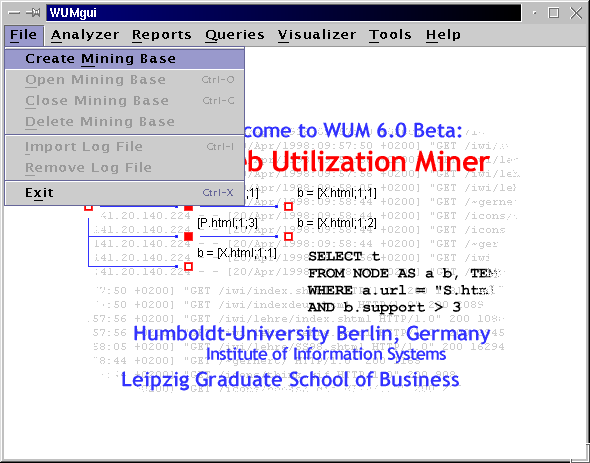
There are five text fields for the parameters of the new mining base. Each mining base must have a unique name that may include blank spaces and numbers. The corresponding web server URL can optionally be stored for future use.
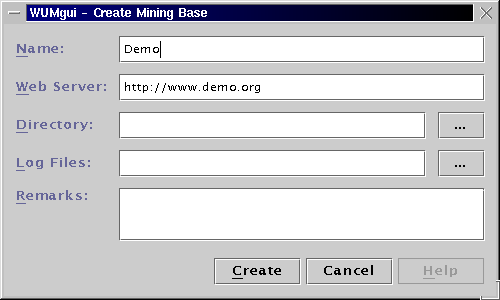
Each mining base must have its own directory to store the database and
other related files. It is recommended to create a subdirectory in the
directory data for each new mining base before starting the
miner. The mining base of this tutorial will be stored in the existing
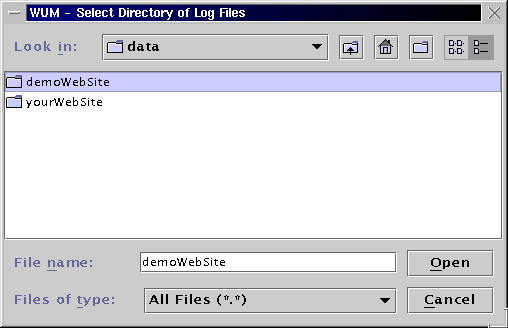
directory data/demoWebSite. Click on the button (Directory)
... to open a file dialog of your operating system. In order to select
the necessary directory websites/demoWebSite, please select the
directory and click OK. Alternatively, the name of an existing
directory can be entered in the corresponding text field.
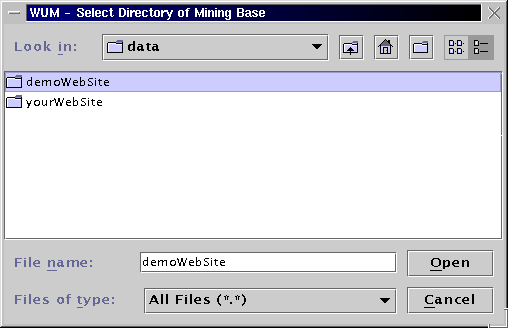
After selecting or entering the home directory of the new mining base, the current dialog should - more or less - look like this:
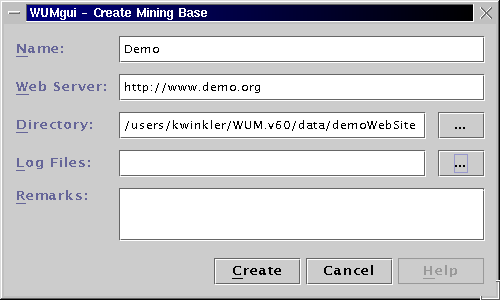
Additionally, the local directory containing the log files of your Web
server must be specified. The demo log file AccessLog.txt
is stored in the same directory as the database. Therefore, click on the
button (Log Files:) ... to open the file dialog of your operating
system. Open the directory data/demoWebSite and finally
click OK. to select the log file directory.
After checking the entered parameters, please click the button OK in order to create the new mining base for this tutorial. Clicking Cancel would abort the creation of a new mining base. In this case, the focus would be returned to the main window of WUM.
After successfully creating a new mining base, the title of the
main window contains the name of the new mining base in brackets. The new
mining base is now open and can be used for further operations. There can be
only one open mining base at a time. The Object Store PSE Pro database
consists of three files WUM.MiningBase.* that are stored in the
same directory. Please do not edit, modify or delete these files.
Please note that the underlying Object Store PSE Pro is a single user
database only. The DBMS of Object Store PSE Pro uses a locking mechanism to
secure that each mining base is accessed by exactly one user at a time. The
database of an open mining base is locked by creating a subdirectory
WUM.MiningBase.odx in its home directory.
If the previous mining session ended abnormally, the lock directory can be deleted by WUM in order to start the miner. Before unlocking a database by force, make sure that there is no other user working with the corresponding mining base.
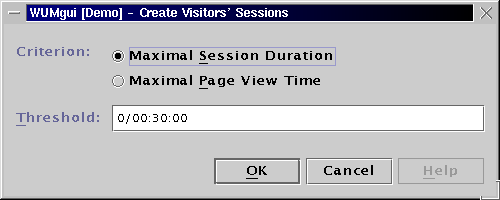
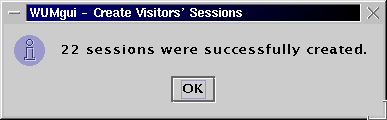
After creating a new or opening an allready existing mining base, HTTP server log files with increasing time stamps can subsequently be imported into the mining base. The import module performs basic data cleaning operations on each log file line and updates the database with data of new visitors and Web pages. In order to import the small demo log file into the tutorial mining base, please open the File menu and select Import Log File.
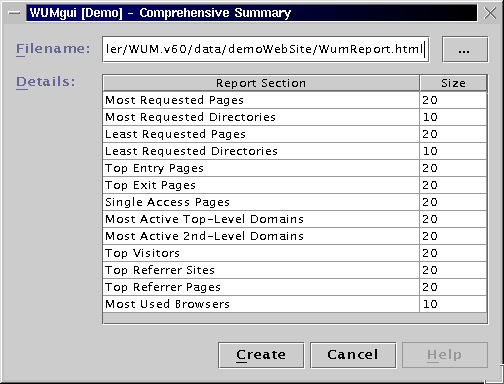
The user interface of the import module is depicted in the next picture. There are a few parameters that must be specified by the user before a log file can be imported. Apart from simply entering the log file name and its format, all parameters concerning the data cleaning process should be considered very carefully.
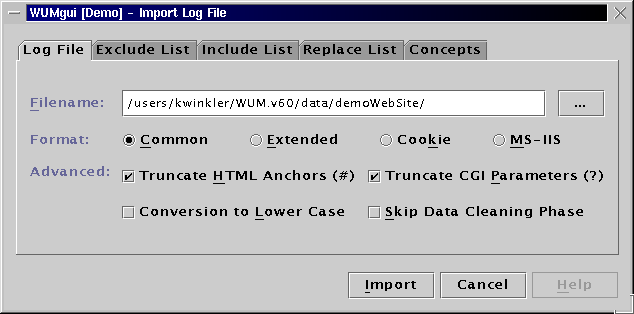
The text field Filename contains the default directory of HTTP server log files. By clicking the button (Filename) ..., you can specify the log file to be imported using the file dialog of your operating system. After choosing the correct file and clicking OK, the complete log file name will be shown in the text field.
WUM currently supports four wide-spread log file formats. There is an
example log file line of each file format in the following table: The
example log file AccessLog.txt corresponds to the common log
file format. Therefore, please check the Common Log File radio button.
The following table contains an example log file line for each log file
format supported by WUM:
| Common | picasso.wiwi.hu-berlin.de
- - [10/Dec/1999:23:06:31 +0200] "GET /index.html HTTP/1.0"
200 3540 |
| Extended | picasso.wiwi.hu-berlin.de
- - [10/Dec/1999:23:06:31 +0200] "GET /index.html HTTP/1.0"
200 3540 "http://www.berlin.de/" "Mozilla/3.01 (Win95;
I)" |
| Cookie | picasso.wiwi.hu-berlin.de
- - [10/Dec/1999:23:06:31 +0200] "GET /index.html HTTP/1.0"
200 3540 "http://www.berlin.de/" "Mozilla/3.01 (Win95;
I)" "VisitorID=10001; SessionID=20001" |
| MS-IIS | picasso.wiwi.hu-berlin.de,
-, 10.12.99, 23:06:31, W3SVC2, WWW, 100.100.100.100, 547, 444, 0, 200,
0, GET, /index.html, -, |
In order to reduce the number of web pages within the WUM database, HTTP requests can be truncated by cutting of all characters starting at the first occurence of '#' (HTML anchors) or '?' (CGI parameters). Examples: If the option Truncate Requests: HTML Anchors is enabled, the requests "GET /contact.html#address" and "Get /contact.html#email" will both be shortened to "GET /contact.html" and will therefore be treated as requests concerning the same web page. If the option Truncate Requests: CGI Parameter is enabled, the requests "POST /cgi-bin/download.cgi?userid=123&version=a" and "POST /cgi-bin/download.cgi?userid=456&version=b" will both be shortened to "POST /cgi-bin/download.cgi".
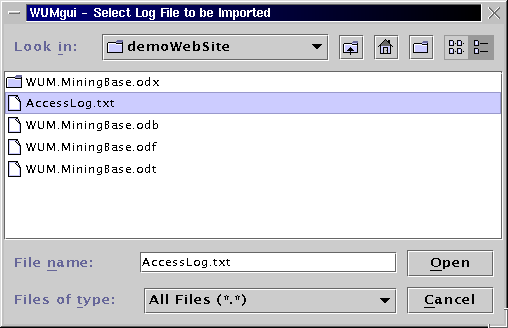
The WUM distribution contains a very small log file AccessLog.txt
that is to be used in this tutorial. [The tutorial is hopefully to be continued
at some point in time. Do you want to help?]
Please keep in mind that the import module of WUM performs only basic substring operations on each log file line. According to the user's individual mining goals, preprocessing the raw log file with the help of user specific Perl scripts etc. can be extremely useful.

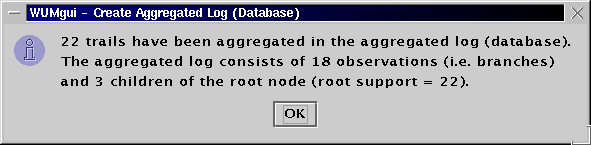
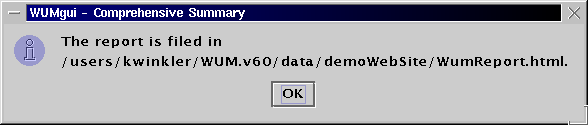
The generated HTML report can be found here.
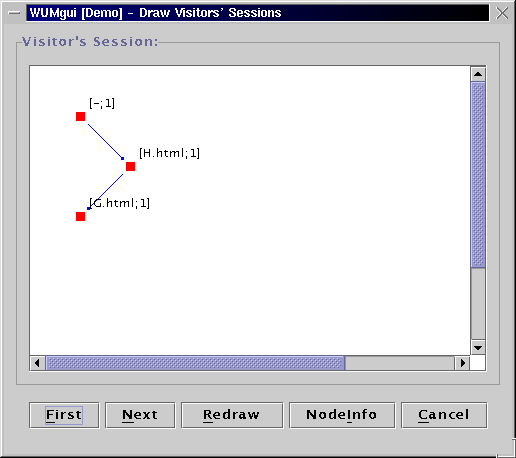
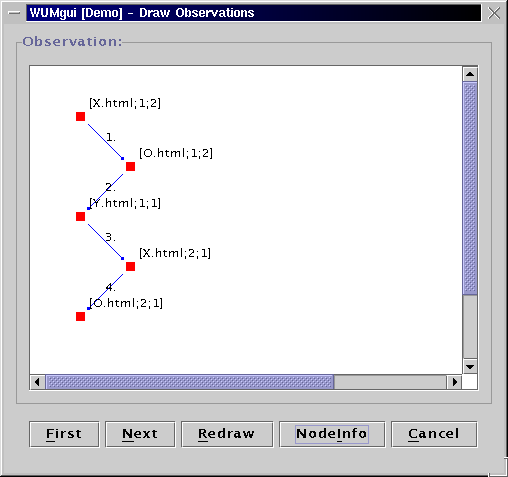
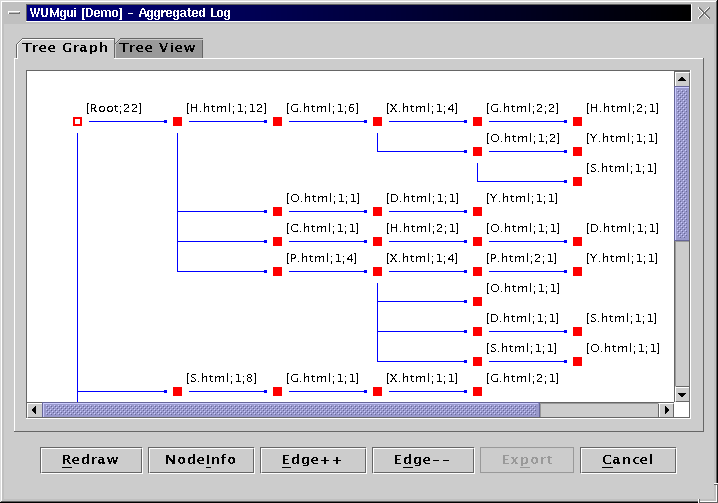
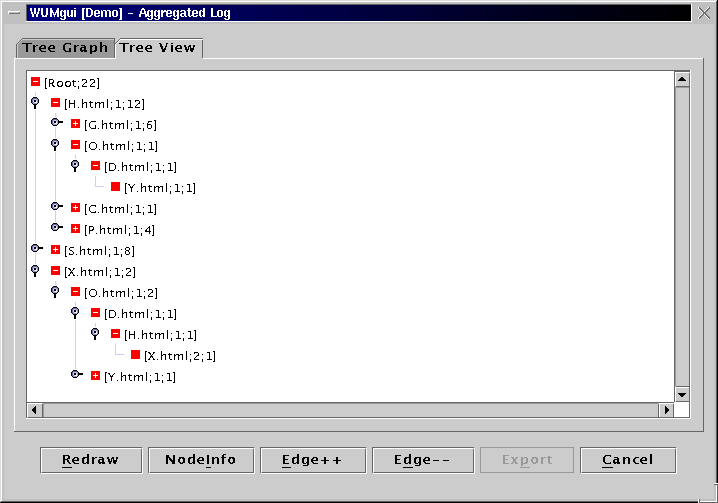
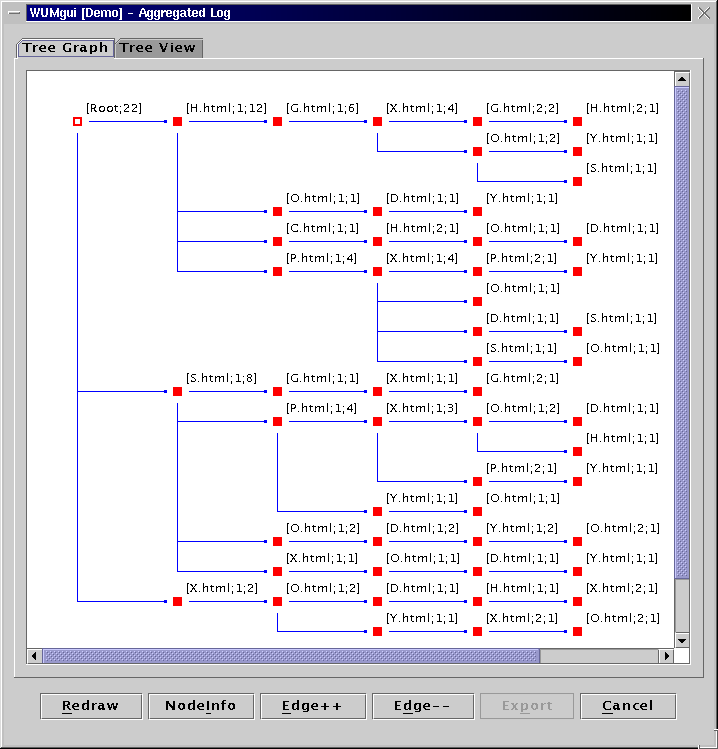
Image of Complete Aggregated Log
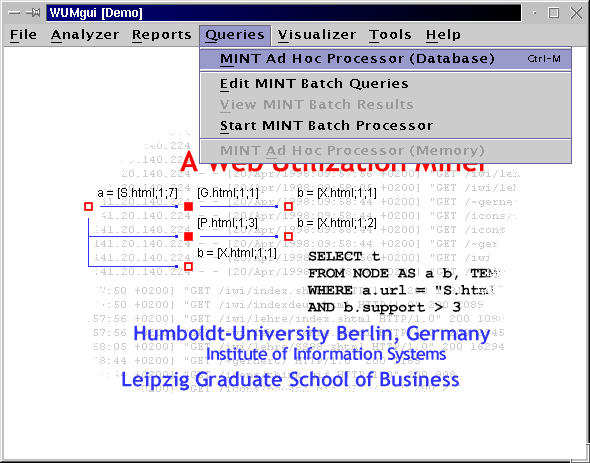
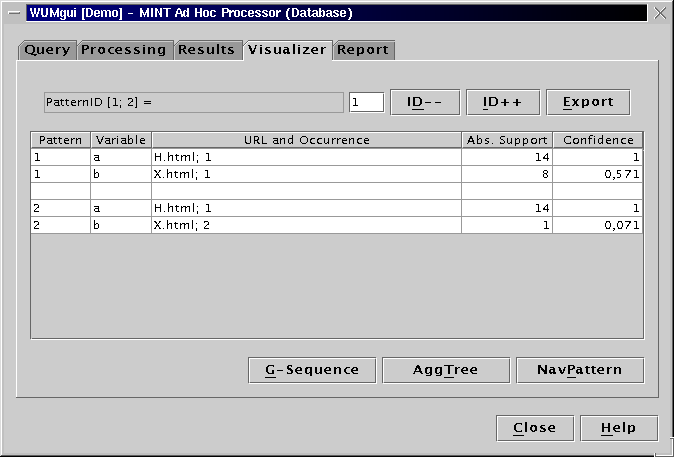
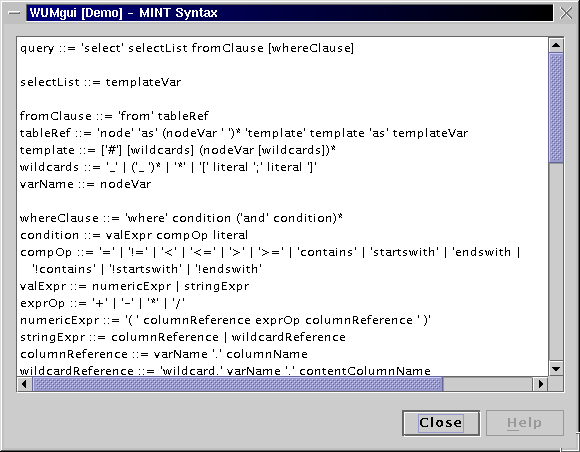
WUM accepts as input a template, i.e. an ordered list of variables and wildcards, and a conjunction of constraints on the statistics of those variables. It finds all sequences, which taken together build a pattern (actually a directed acyclic graph) that satisfies the template and the constraints.
Example: We are interested in an event x that occurs after y with probability at least 95%. This event y should appear in at least 100 of our sequences. x needs not occur immediately after y, but it should not be more than 5 events away from y. This specification produces the template y [0;5] x where x and y are variables. The wildcard [0;5] stands for any number of events, and the interval [0;5] constraints the wildcard between zero and up to 5 events. The constraints on x and y result in two restrictions:
y.support >= 100
and ( x.support / y.support ) > 0.95
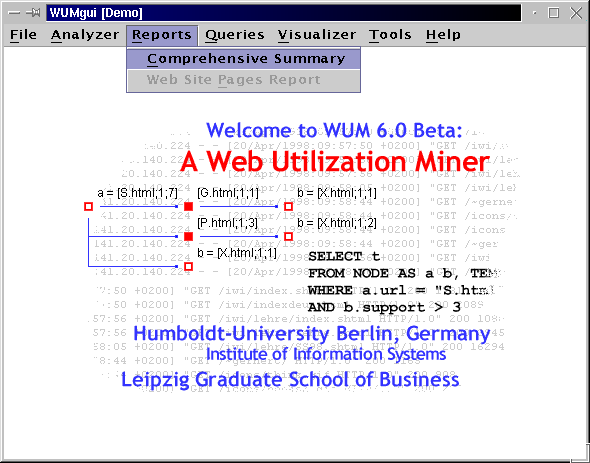
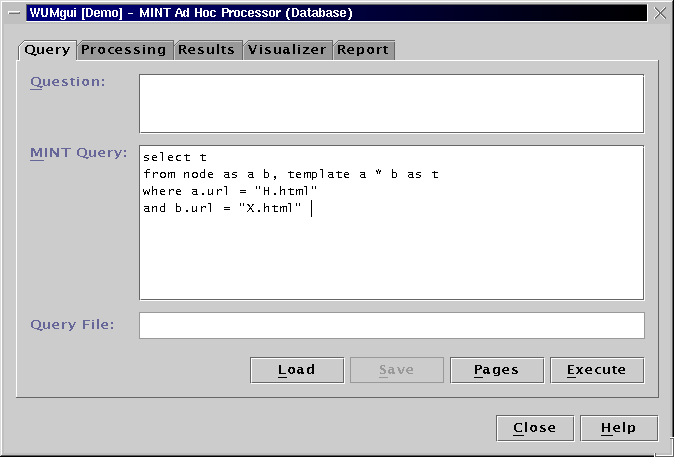
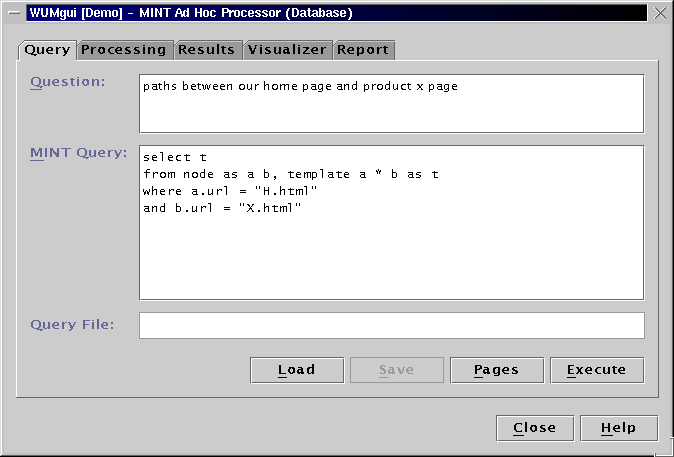
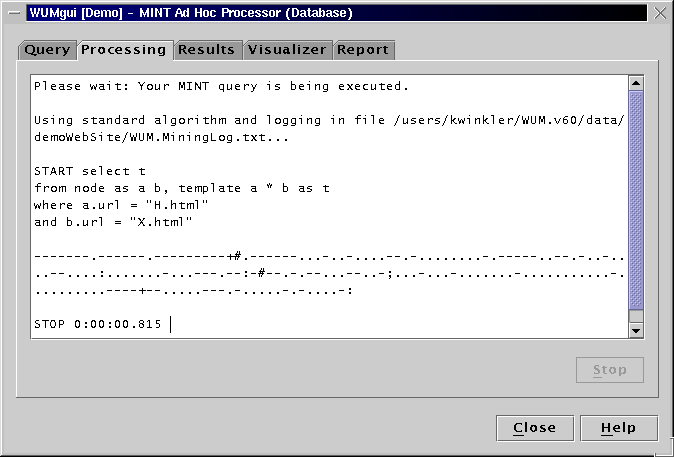
To find the sequences satisfying this template and constraints, issue the following MINT query:
select t
from node as a b, template y [0;5] x as t
where y.support >= 100
and ( x.support / y.support ) > 0.95
You can use this query in the demo. But you have to reduce the support of y, because there is no event that appears in more than 8 sequences. This was just an example. For the formal definitions and the description of the miner at work, please refer to the publications about the Web Utilization Miner WUM.
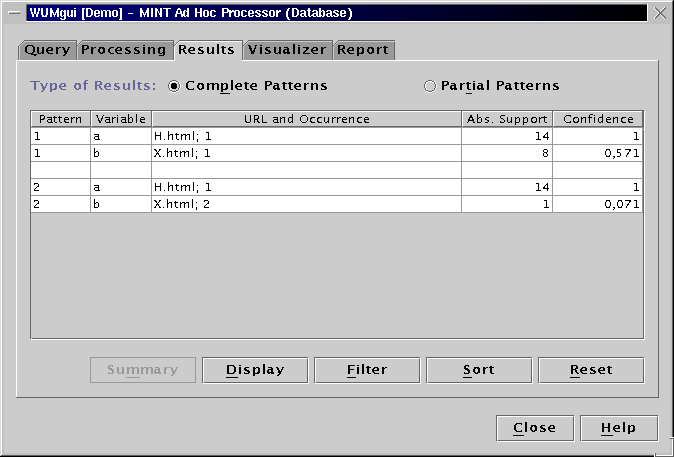
When issuing a MINT query, WUM finds all acceptable bindings for the template variables. A binding is a list of events, i.e. of values, bound to the variables. A binding is acceptable if the events comprising it appear in sequences which:
conform to the template's structure
taken together constitute a group, the statistics of which satisfy the query constraints
In the above example, a URL "Y.html" in the dataset could be bound to variable y. A URL "X.html" could then be bound to x, only if there exists a sequence where X.html appears within 6 positions after Y.html. For the binding to be acceptable, there should be at least 100 sequences containing Y.html and 95 of them should contain X.html in at most 6 positions after Y.html. Those sequences "contribute" the binding (Y.html, X.html).
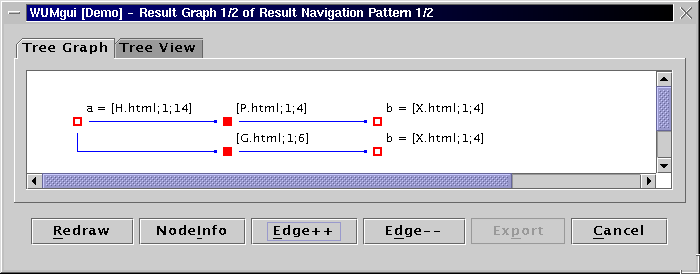
WUM discovers all acceptable bindings for the query and builds a "navigation pattern" for each binding. A navigation pattern is a directed acyclic graph comprised of the sequences contributing the binding: the sequences have been merged at common prefix and at each event of the binding.
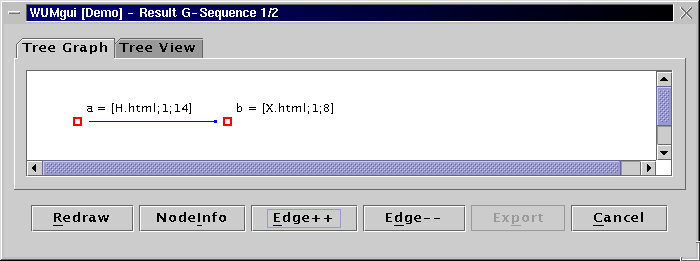
The visualization tool of WUM can display a navigation pattern in two ways:
The "template tree" consists only of the events comprising
the binding. The events are annotated with the number of contributing
sequences.
This format gives an overview of the events that satisfy our query,
without information on the surrounding events.
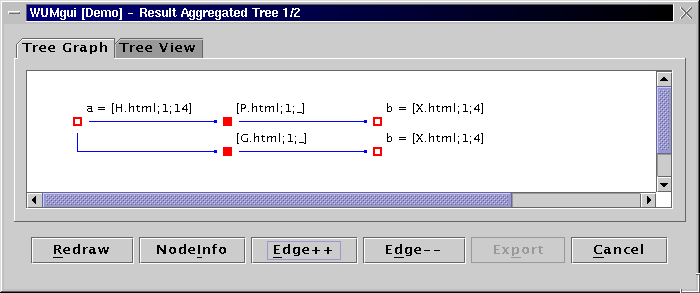
An "aggregate tree" is a set of subsequences merged on
common prefix. For two consecutive events in the binding, the aggregate
tree shows the fragments of the contributing sequences between
those two events.
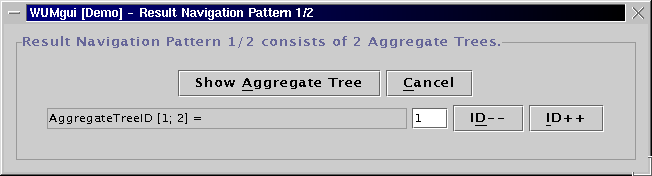
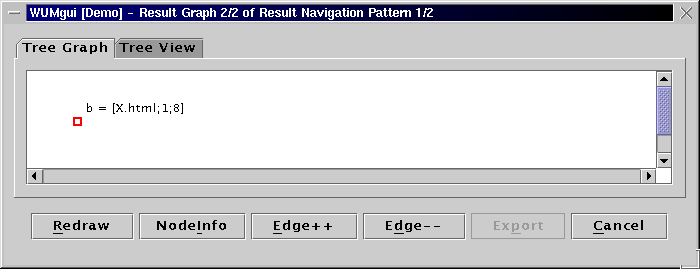
WUM cannot yet display graphs. So, a navigation pattern is
split into aggregate trees, one per event in the binding. This
event is then the root of the aggregate tree.
| Top of the Page • Legal Notice | December 3, 2004 |
{kind=link}